Fiabilité et Sécurité des Applications
Réplication et Scaling
Emmanuel COQUERY
2023-04-24 – TIW-FSA
Introduction
Scaling
- Augmenter la puissance / robustesse d’un déploiement
- Pour répondre à plus de solicitations
- Pour résister aux pannes
- Pour résister aux attaques
Typologies de scaling
vertical: augmenter la puissance de chaque machine
- limite matérielle
- faible protection contre les pannes
horizontal: augmenter le nombre d’instances
- plus complexe à mettre en œuvre
- moins de limites matérielles
Scaling horizontal: cube

Scaling et fiabilité
Axe X
- Clones équivalents, interchangeables
- Fiabilité accrue
- de part l’interchangeabilité
- Facile à déployer (ajout d’un load-balancer)
- Pas toujours possible mettre en œuvre
- compliqué pour des composants stateful
Axe X: cas des bases de données
- Peut-être complexe au niveau bases de données
- tous les réplicats doivent pouvoir écrire
- problématiques de cohérence
- Compromis intéressants sur des BD non-traditionnelles
- Redis, MongoDB, Cassandra, etc
- Modèle reine-princesses, avec princesses utilisées en lecture
- si le ratio lecture/écriture est élevé
Axe X: exemples
- clonage d’un serveur web (sans sessions gérées en interne)
- workers
- bases de données répliquées
Axe Y
- Décomposition par fonctionnalité et/ou domaine
- Meilleure possibilité d’isolation des problèmes
- Peut permettre de suivre d’autres axes
- Les bases de données peuvent être découpées si le modèle de données
le permet
- si certaines parties ne sont pas reliées dans les requêtes
- Attention aux erreurs en cascade
- Déploiements complexes
Axe Y: exemples
- séparation persistence-calcul
- séparation frontend/backend
- séparation utilisateur/produits
- plus généralement: décomposition en micro-services
Axe Z
- Décomposition en groupes similaires
- par tenant: groupe organisationnel
- distribution selon une clé de répartition (e.g. hash)
- Souvent appliquée sur les données
- Indépendances des instances
- tolérance aux pannes
- meilleure étanchéité pour la confidentialité et l’intégrité
- Pas de garantie supplémentaire au sein d’une instance
- Ne fonctionne bien que si chaque instance peut être gérée indépendamment des autres
Axe Z: exemples
- Décomposition par utilisateur via hash de l’id
- Adhésion de session (par adresse IP)
- Décomposition par organisation
- Bases de données réparties via décomposition horizontale (sharding)
Combiner plusieurs axes
- Découper par fonctionnalité (Y) permet ensuite de cloner (X) / distribuer (Z)
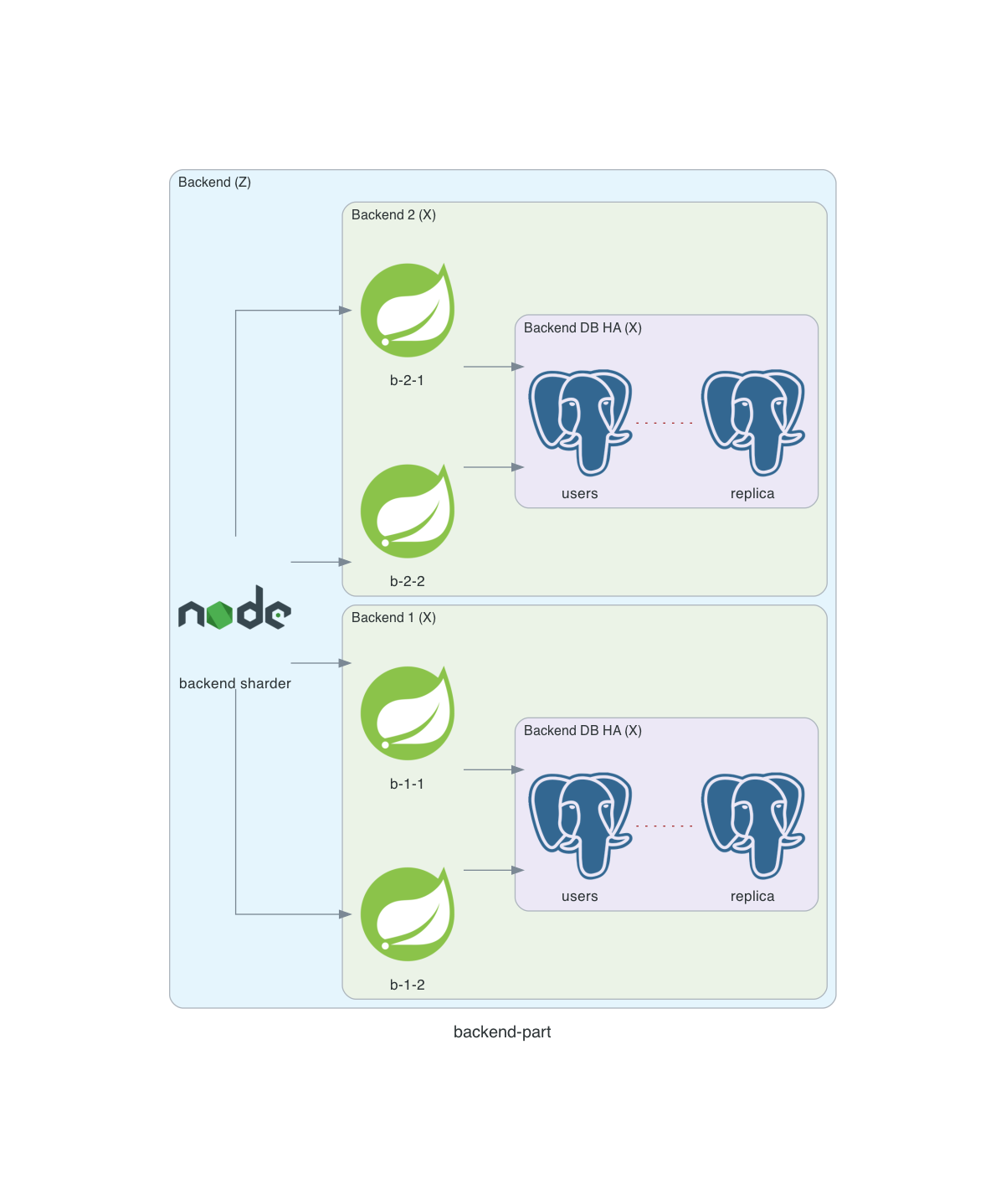
- Possibilité de combiner X avec Z pour augmenter la fiabilité
- ex: MongoDB: répartition en “shards” composés de “replica sets”
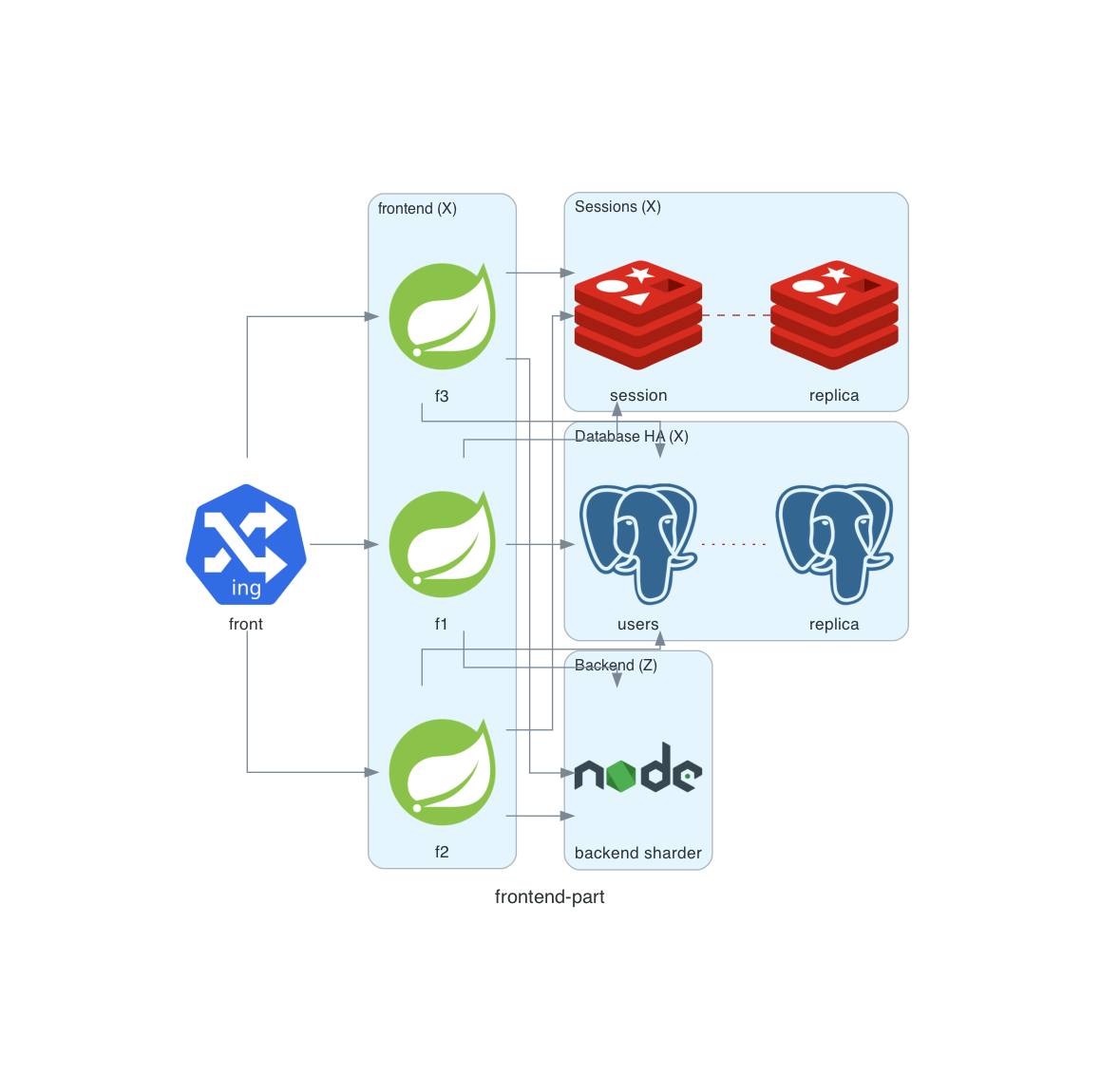
Exemple
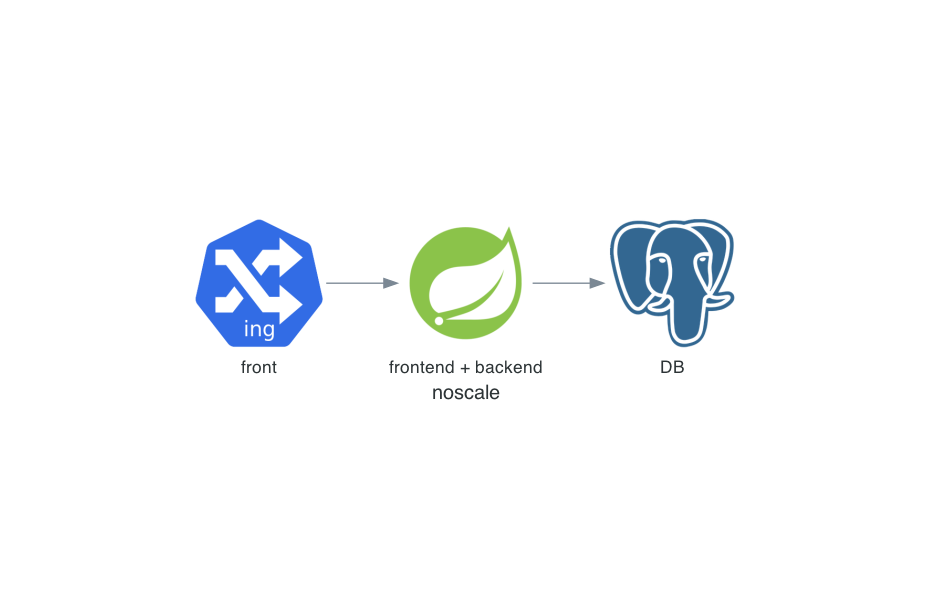
Exemple - front
Exemple - back